











범용 프로세서를 중심으로 하는 현재의 컴퓨터 아키텍처는 기본적으로 모든 작업을 다룰 수 있지만, 모든 작업을 효율적으로 다루지는 못한다. 이에, 높은 성능이 필요한 새로운 유형의 작업에 반도체의 물리적 성능 향상을 통한 범용적인 평균 성능 향상 이상의 성능 향상을 제공하기 위한 방법으로 ‘워크로드 최적화’ 구성이 중요해지고 있다. 이 ‘워크로드 최적화’는 높은 성능이 필요한 새로운 유형의 작업에 효율적인 처리를 지원하기 위해 범용 프로세서에서 새로운 명령어 등으로 기능을 확장하거나, 프로세서 외부에 특정 연산 유형에 최적화된 ‘가속기’를 구성함으로써 전체 워크로드 처리에 필요한 시간을 줄이고 처리량을 극대화할 수 있다. 특히, 그래픽 처리를 위한 ‘GPU’는 최근 PC와 데이터센터 모두에서 가속기로도 중요한 역할을 하고 있다.
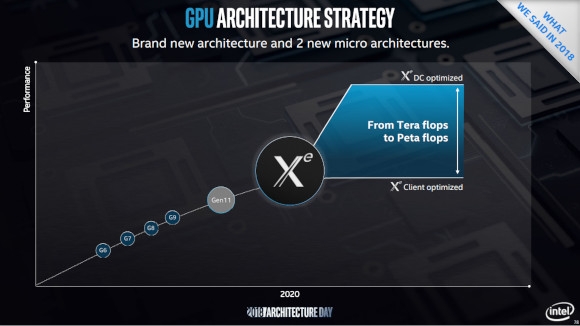
인텔은 모든 유형의 워크로드에서 최적화된 성능을 제공하기 위한 전략으로, 기존의 핵심 역량이던 프로세서가 제공하는 기능을 확장해 더 많은 워크로드 유형에 대응함과 함께, 다양한 형태의 ‘가속기’ 구성을 제공하는 ‘XPU’ 전략을 소개한 바 있다. 이 전략에서, 현재 극도로 병렬화된 연산을 빠르게 처리하는 데 있어 범용성을 갖춘 가속기로 중요한 위치에 있는 GPU의 존재는 ‘데이터 중심’의 시대를 위한 포트폴리오를 완성하는 마지막 퍼즐의 의미를 지니고 있다. 그리고, 지난 20여 년간 인텔은 GPU와 관련해 다양한 시도를 해 온 바 있지만, 내부적으로 12세대로 분류하는 ‘Xe’ 아키텍처는 프로세서와 플랫폼의 기본 내장 그래픽을 넘어 고성능 게이밍과 데이터센터의 연산용 GPU에 이르기까지 다양한 활용이 가능한 강력한 잠재력을 갖추었다.
 |
| ▲ 인텔의 차세대 전략은 다양한 워크로드 유형에 적합한 ‘가속기’를 조합하는 ‘XPU’ 전략으로 요약된다 (자료제공: Intel) |
컴퓨터로 다루어야 할 문제의 유형이 더욱 다양해지고 있지만, 하나의 범용 프로세서는 모든 작업을 다룰 수는 있겠지만 모든 작업을 효율적으로 다룰 수는 없다. 그리고 이러한 작업 유형에 대한 고민은 프로세서의 코어 수 증가에 따른 멀티코어 최적화의 수준보다 좀 더 근본적인, 연산의 유형에 대한 부분에서부터 시작하기도 한다. 예를 들어, 범용 프로세서의 경우 대개 스칼라 연산에 적합한 구조를 가지고 있는데, 이런 구조에서 벡터나 매트릭스 연산 위주의 워크로드는 성능 효율이 극히 떨어진다. 또한 높은 정밀도의 연산에 적합하게 구성된 범용 프로세서의 구조는, 낮은 정밀도의 간단한 연산을 대량으로 동시 수행하는 상황에서 그리 효율적이지 못할 것이다.
지금까지 범용 프로세서는 하나의 프로세서로 다양한 연산을 수행하면서 이러한 다양한 연산 유형에 대응할 수 있도록 그 역량을 점차적으로 확장해 왔다. 대표적인 사례가 인텔의 프로세서에 있는 SSE, AVX 관련 명령어들인데, 이 명령어들을 활용해 벡터 연산 위주의 작업에서 프로세서의 처리 효율을 크게 높여 온 바 있고, 차세대 프로세서들에 탑재될 ‘골든 코브(Golden Cove)’에는 AMX(Advanced Matrix eXtensions) 명령어로 행렬 연산에서 반복 작업으로 인한 시간 낭비를 줄이고 성능을 크게 높일 수 있게 했다. 또한 암호화 등 많은 워크로드에서 공통적으로 활용되는 작업은 AES-NI 등의 명령어를 통해 더욱 빠르게 처리할 수 있도록 했다. 이러한 프로세서의 확장은 하나의 프로세서가 효율적으로 처리할 수 있는 작업의 폭을 크게 넓혔다.
특정 유형의 작업에 최적화된 별도의 처리 엔진을 조합하는 ‘가속기’는 컴퓨팅 성능의 사용 용도가 분명히 특정되는 경우 아주 효율적인 방법이다. 현재 가장 보편화된 가속기 유형은 GPU일 텐데, 이 GPU는 예전에 프로세서가 처리하던 2D, 3D 그래픽 연산 과정의 대부분을 하드웨어 기반으로 처리하고, 이제는 동영상의 디코딩과 인코딩, 후처리 과정을 위한 엔진까지 포함하고 있다. 특히 3D 그래픽 처리의 경우, 아무리 기본적인 성능을 갖춘 프로세서 내장 GPU라 해도 프로세서만을 활용한 처리와는 비교하기 힘들 정도로 빠르며, 고성능의 GPU는 프로세서로는 한 장의 렌더링에도 몇 분이 걸릴 화면을 초당 수백 장씩 처리할 수 있을 정도다.
처음에는 3D 그래픽의 구현에 집중했던 GPU는 이제 상당한 범용성을 가진 ‘가속기’로도 활발히 활용되고 있다. 엔비디아(NVIDIA)가 2006년 지포스(GeForce) 8000 시리즈와 함께 선보였던 CUDA 이후, 이제 GPU는 그래픽 처리 뿐 아니라 AI 워크로드 등 극도의 병렬 처리 환경에 최적화된 특정 유형의 연산을 위한 가속기로도 본격적으로 사용되고 있다. PC 환경에서도 GPU는 고성능 게이밍 환경 뿐 아니라 미디어 콘텐츠 제작 환경에서도 성능과 생산성을 크게 높이는 가속기로 중요한 역할을 하고 있는데, 어도비 프리미어나 다빈치 리졸브 등의 영상 제작 환경에서 GPU는 복잡한 작업 환경에서의 실시간 프리뷰나 필터 적용에서의 높은 연산 성능 제공, 렌더링 과정에서 더 빠른 작업 완료 등의 혜택을 제공하고 있다.
 |
| ▲ 인텔의 GPU 역사에서, Xe 아키텍처는 여러 가지로 큰 변화와 도전의 계기로 꼽힌다 (자료제공: Intel) |
GPU 시장에서 인텔은 제법 오랜 역사를 가지고 있으며, 첫 세대는 펜티엄 2를 위한 440LX 칩셋에서 선보인 AGP 버스 활용의 레퍼런스이기도 했던 1998년의 i740에서부터 시작한다. 이 i740의 기원을 따지면, 지금은 록히드 마틴에 인수된 ‘GE Aerospace’의 시뮬레이터 기술에서부터 출발하지만, 결과적으로는 당시 빠르게 바뀌어 가던 PC 게이밍 시장에서 경쟁력을 지속적으로 유지하지는 못했었다. 그리고 1세대의 i740 이후부터, 인텔은 플랫폼에 내장된 GPU로써 지속적으로 기술을 개발해 왔으며, 4세대 모델부터는 DirectX 10지원과 제법 훌륭한 H.264 영상 디코딩 기능 등을 제공했고, 2세대 코어 프로세서에서부터 사용된 6세대 모델 이후부터는 당대의 최신 운영체제들에서 요구되는 기본적인 기술적, 성능적 요구를 충실히 만족시켜 온 바 있다.
이러한 인텔의 GPU 역사 속에서, 인텔이 다시금 게이밍이나 연산 등을 위한 ‘고성능’ GPU를 만들려는 시도는 몇 번이고 있었지만, 그리 성공적이지 못했다. 특히 인텔이 2006년부터 진행해 온 것으로 알려진 ‘라라비(Larrabee)’ 프로젝트는 극도로 단순화된 x86 아키텍처 기반의 매니 코어 구성으로 고성능 GPU 시장에 접근한다는 방향성을 제시했지만, 결국 그래픽 용도로는 활용되지 못하고 연산 가속기로써의 ‘제온 파이(Xeon Phi)’ 제품군으로 선보였던 바 있다. 이런 시도는 당시 x86 아키텍처를 다양한 용도로 활용할 수 있도록 시장을 확장하는 전략에 따른 것이기도 했는데, 태블릿과 스마트폰 등을 위한 모바일용 SoC에도 x86 기반 ‘아톰(Atom)’ 프로세서 시리즈가 투입되기도 했지만, 결과적으로는 그리 성공적이지 못했다.
한편, 프로세서 내장 그래픽에서도 차별화된 성능을 위한 시도도 있었는데, 모바일용 프로세서들에서 찾아볼 수 있는 EU 슬라이스를 대폭 확장한 GT3, 부족한 메모리 대역폭을 극복하기 위해 그래픽과 프로세서가 공유할 수 있는 eDRAM을 탑재한 구성 등이 그것이다. 또한 프로세서 내장 그래픽에서도 전문 그래픽 작업을 위한 호환성 인증을 갖춘 P 시리즈도 엔트리급 워크스테이션을 위한 제온 프로세서에서 나름대로의 가치를 제공해 왔다. 그리고, 인텔의 프로세서 내장 GPU에서도 3세대 코어 프로세서 ‘아이비 브릿지’부터 탑재된 ‘7세대’ 모델부터는 OpenCL API를 통해 GPU 연산을 지원하기 시작했으며, 이후 세대가 바뀔 때마다 성능이 개선되면서, 콘텐츠 제작 환경 등에서도 제법 실용적인 하드웨어 가속 기능의 혜택을 제공했다.
11세대 코어 프로세서 제품에서 선보인 12세대 ‘Xe’ 아키텍처는 지금까지의 인텔 GPU 역사에서도 다시금 중요한 변화의 계기가 되고 있다. 라자 코두리(Raja Koduri) 수석 부사장의 영입 이후 새롭게 등장한 Xe 아키텍처는 기존보다 더욱 일반적인 GPU에 가까운 특징을 갖추었으며, 단일 아키텍처 기반에서 프로세서 내장 그래픽에서 슈퍼컴퓨터의 연산 가속을 위한 초대형 GPU에 이르기까지 폭넓은 시장에 대응할 수 있는 유연성을 갖추었다. 이에, 인텔은 단일 Xe 아키텍처를 기반으로 프로세서 내장 그래픽 수준의 LP, 고성능 PC 게이밍을 위한 HPG, 데이터센터를 위한 HP, 고성능 컴퓨팅을 위한 HPC 등 크게 네 가지 유형의 GPU를 내놓으며, 컴퓨팅 환경 전반에서 실질적인 ‘XPU’ 전략의 큰 틀을 완성할 수 있을 좋은 기회를 맞았다.
 |
| ▲ 인텔은 ‘아크(Arc)’ 브랜드로 게이밍용 고성능 GPU 시장에 다시 도전한다 (자료제공: Intel) |
 |
| ▲ 매트릭스 엔진을 활용하는 XeSS는 벡터 엔진을 활용할 때보다 성능 효율이 높다 (자료제공: Intel) |
인텔의 Xe 아키텍처 기반 GPU는 동일 아키텍처 기반에서 다양한 빌딩 블록의 조합으로 네 가지 유형의 GPU를 만들어 낸다. 이에, 현재 11세대 코어 프로세서의 내장 그래픽이나 노트북 PC의 외장 그래픽, 서버용 GPU 가속기 등으로 사용되는 Xe LP 계열 GPU와, 향후 선보일 고성능 게이밍용 GPU인 Xe HPG, 슈퍼컴퓨터의 연산 가속을 위한 Xe HPC 모두에서, 아키텍처 차원의 공통적인 기술적 특징을 발견할 수 있다. 하지만 인텔은 아키텍처의 유연성을 통해, 이 네 가지 유형의 GPU가 동일한 아키텍처를 기반으로 하지만, 빌딩 블록들의 조합과 구성으로 전혀 다른 수준의 성능과 기능, 특성을 가지는 GPU 제품군을 구성했다. 또한, 제품의 특성에 따라, 각 제품군별 제조 공정이 완전히 다른 것도 Xe 아키텍처 기반 GPU들에서 찾을 수 있는 특징이다.
Xe LP와 Xe HPG는 모두 PC 시장 쪽과 그래픽 워크로드의 가속에 중점을 두는 것은 동일하지만, Xe HPG에서는 목표하는 시장에서 요구되는 기능과 성능 수준에 대응하기 위해 새롭게 구성된 부분들을 확인할 수 있다. 이 때, 아키텍처의 근간이 되는 EU(Execution Unit)와 서브시스템 구성은 LP와 HPG가 거의 동일한 구성인데, HPG의 기본 근간이 되는 256비트 폭의 벡터 엔진은 기존의 EU에 대응되는 개념이고, 샘플러나 픽셀 백엔드 등 서브시스템의 구성 역시 Xe LP와 Xe HPG 사이에 동일한 형태로 공유되는 모습이다. 하지만, Xe LP에서는 32 EU 단위로 내부 구조를 확장하는 형태였지만, Xe HPG는 Xe-코어 4개에 해당하는 64 벡터 유닛 단위로 렌더 슬라이스를 구성한 것이 차이점이다.
또한, Xe HPG는 현재 시장에서 경쟁이 예상되는 최신 GPU들에 대응하기 위해 LP 대비 몇 가지 중요한 특징들이 추가되었다. 먼저, Xe HPG의 코어 수준에서는 벡터 유닛 하나당 1024비트 폭의 ‘매트릭스 엔진(Matrix Engine)’ 하나가 구성되어, Xe-코어당 16개의 벡터 엔진, 16개의 매트릭스 엔진이 내장된다. 이 매트릭스 엔진은 AI 워크로드 연산 등에 뛰어난 성능을 제공하며, Xe HPG에서는 이를 통해 딥러닝 기반 슈퍼샘플링 기술인 XeSS(Xe Super Sampling)을 제공한다. 이 XeSS 기술은 Xe HPG의 매트릭스 엔진을 활용하거나, 혹은 기존의 벡터 엔진에 DP4a 기반으로 구현할 수도 있는데, 매트릭스 엔진을 활용하는 경우 4K 업샘플링에서 성능에 대한 부담이 더 적은 것으로 알려져 있다.
 |
| ▲ Xe HPG는 최신 게이밍 환경을 위한 레이 트레이싱과 DirectX 12 얼티밋 규격을 충족시킨다 (자료제공: Intel) |
Xe HPG에는 윈도우 11에서 사용할 수 있는 최신 API 규격인 DirectX 12 얼티밋(Ultimate)을 지원하기 위한 부분도 적용되어 있다. 가장 먼저 확인할 수 있는 것은 ‘레이 트레이싱 유닛(Ray Tracing Unit)’으로, 이는 렌더 슬라이스 상에서 Xe 코어당 한 개씩, 하나의 슬라이스에는 총 네 개의 유닛이 탑재된다. 이 레이 트레이싱 유닛을 갖춤으로써, Xe HPG는 완전한 DirectX 12 얼티밋 환경의 지원과 함께 현재의 게이밍 GPU 시장에서 경쟁 제품들과 동등한 기술 지원 수준으로 경쟁할 수 있는 여건을 갖췄다. 이 외에도 개별 Xe 코어당 하나씩 할당되는 샘플러, Xe 코어 두 개당 하나씩 구성되는 픽셀 백엔드, 렌더 슬라이스당 하나씩 구성되는 지오메트리, 래스터라이제이션 파이프라인, HiZ 등도 DirectX 12 얼티밋 환경을 지원할 수 있게 마련되었다.
Xe HPG의 그래픽 엔진 확장에서 기본 단위는 4개의 Xe-코어로 64개의 벡터 엔진, 64개 매트릭스 엔진, 4개의 레이 트레이싱 유닛을 갖춘 ‘렌더 슬라이스’로, 공유 L2 캐시와 메모리 패브릭을 통해 최대 8개까지 확장할 수 있다. 최대 구성인 8개 렌더 슬라이스까지 확장하는 경우 갖출 수 있는 구성은 512개의 벡터 엔진과 매트릭스 엔진, 32개의 레이 트레이싱 유닛 구성이 된다. 그리고 현재 제품화가 기대되는 구성은 2개 슬라이스의 128 벡터 엔진 구성을 엔트리 급으로, 4~6개 슬라이스로 256~384 벡터 엔진 구성을 메인스트림 급으로, 8개 슬라이스의 512 벡터 엔진 구성을 하이엔드 급으로 선보일 것으로 예상된다. 그리고 그래픽 메모리 버스 또한 최대 256비트 폭까지 확장될 것으로 알려져 있다.
한편, 인텔은 이 Xe HPG의 브랜드명을 ‘아크(Arc)’로, 첫 제품명을 ‘알케미스트(Alchemist)’로 발표하고, 2022년 1분기 제품 출시를 목표로 한다고 발표한 바 있으며 차세대 Xe 아키텍처를 기반으로 꾸준히 게이밍용 GPU를 선보일 것이라는 계획을 선보이기도 했다. 또한 인텔의 역사에서 중요한 도전이 될 Xe HPG의 생산은 인텔이 아닌 TSMC의 N6 공정이 사용될 예정인데, 이는 GPU회로의 특성과 제조 역량 등 다양한 부분에서 고려된 결과로 보인다. 그리고, 이 Xe HPG는 아키텍처와 로직 디자인, 회로 디자인, 제조 공정과 소프트웨어 등에 이르기까지 다양한 영역에서의 최적화를 통해, 기존의 Xe LP를 기반으로 하는 Iris Xe Max 등 외장 그래픽 구성과 비교할 때 비슷한 전압에서 1.5배의 동작 속도와 1.5배의 전력 효율을 보여줄 것으로 기대된다.
 |
| ▲ 연산을 위한 GPU인 Xe HPC는 Xe 아키텍처 기반에서 벡터와 매트릭스 엔진의 폭을 대폭 확장했다 (자료제공: Intel) |
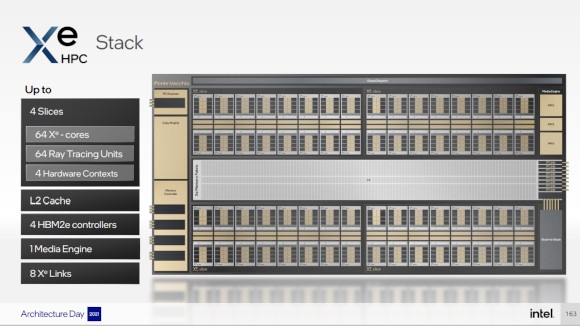 |
| ▲ Xe HPC의 스택은 최대 64 Xe 코어, 512개의 벡터, 매트릭스 엔진을 포함하며, 패키징당 두 개의 스택까지 적층 구성 가능하다 (자료제공: Intel) |
슈퍼컴퓨터 등에서의 고성능 연산 가속을 위한 GPU인 Xe HPC는 Xe 아키텍처를 기반으로 연산 성능에 초점을 맞춘 구성을 갖추고 있으며, Xe 아키텍처의 높은 유연성과 확장성을 실제로 증명하는 존재이기도 하다. 사실 11세대 코어 프로세서의 내장 그래픽과 고성능 게이밍을 위한 Xe HPG ‘아크’, 슈퍼컴퓨터급 연산을 위한 Xe HPC ‘폰테 베키오(Ponte Vecchio)’는, 같은 Xe 아키텍처를 기반으로 하고 있다지만 지원 기능이나 구성 등에서 완전히 다른 성격의 GPU라고 해도 될 정도다. 특히 ‘폰테 베키오’는 Xe 아키텍처의 확장 뿐 아니라, 제조 공정 차원에서도 다양한 빌딩 블록을 ‘타일’ 형태로 제작해 2D, 3D 패키징 기술로 결합하는 독특한 제조 방법을 사용하는데, 이는 추후 제품군 다변화나 설계 변경 등에서 더 유연한 접근이 가능할 것으로 기대된다.
Xe HPC 또한 아키텍처의 시작은 Xe 코어 블록에서부터 시작하며, Xe 코어를 기반으로 하지만 ‘연산’에 특화된 구성을 갖추고 있는 것이 특징이다. Xe HPC의 Xe 코어는 8개의 512비트 벡터 엔진과 8개의 4096비트 매트릭스 엔진을 갖추고 있는데, HPG와 비교하면 벡터 엔진의 수는 절반, 폭은 두 배가 되었고, 매트릭스 엔진은 수는 절반, 폭은 네 배가 된 모습이다. 이에, Xe HPC의 경우는 Xe 아키텍처의 근간이 되는 256비트 벡터 엔진 두 개를 하나로 묶고, 매트릭스 엔진은 기존 블록의 확장형을 사용하는 것으로 보인다. 이렇게 생각할 수 있는 근거는 벡터 엔진의 클럭당 명령어 수를 꼽을 수가 있는데, Xe HPC는 코어 블록당 FP32와 FP64의 클록당 처리 명령어 수가 256개로 같고, FP16에서 512개다.
연산에 특화된 ‘Xe HPC’가 벡터, 매트릭스 엔진이 다룰 수 있는 벡터 폭을 넓힌 것은, 더욱 큰 규모의 문제를 좀 더 수월하게, 정밀하게 다루기 위한 선택일 것이다. 사실 고성능 게이밍 등을 위한 3D 그래픽 연산에서 중요한 것은 ‘적당한 정밀도에서 많은 수의 유닛에 분산 배치를 통한 높은 성능’으로, 이에 Xe 아키텍처의 기본 구조는 FP32 기반 쉐이더 8개로 구성되는 256비트 벡터 엔진이다. 하지만 연산 용도에서는 벡터 폭이 넓으면 더욱 큰 규모의 문제에 편리하게 접근할 수 있고, 연산에 요구되는 좀 더 높은 정밀도 요구에도 대응할 수 있을 것이고, 이에 어느 정도의 오버헤드를 감수하더라도 새로운 벡터 엔진 설계 없이, 기존의 256비트 벡터 유닛 두 개를 결합해 하나의 512비트 유닛으로 사용하는 것은 여러 모로 합리적인 선택이다. 프로세서 쪽에서도, 256비트 AVX2 FMA 유닛을 결합해 AVX-512를 구현한 사례가 이미 있다.
Xe HPC에서, 하나의 ‘슬라이스’에는 16개의 Xe 코어와 16개의 레이 트레이싱 유닛이 하나의 하드웨어 컨텍스트와 결합되어 구성된다. 그리고 하나의 ‘스택’에는 최대 4개의 슬라이스가 메모리 패브릭과 L2 캐시를 통해 연결될 수 있으며, 이 때 최대 구성은 64개의 Xe 코어로 512개의 벡터 엔진과 매트릭스 엔진, 64개의 레이 트레이싱 유닛, 4개의 하드웨어 컨텍스트가 된다. 또한 외부 메모리와의 연결로는 스택당 4개의 HBM2e 컨트롤러가 탑재되며, 한 개의 미디어 엔진, 그리고 외부와의 확장을 위한 8개의 ‘Xe 링크’ 가 하나의 스택에 구성된다. Xe HPC의 단일 GPU 수준에서 최대 확장은 이 스택 두 개를 3D 패키징 형태로 결합하는 것인데, 이 때는 8개 슬라이스, 8개의 HBM2e 컨트롤러, 16개의 Xe 링크 등, 모든 것이 정확히 두 배로 늘어난다.
 |
| ▲ 최대 8개의 GPU를 연결할 수 있는 ‘Xe 링크’는 슈퍼컴퓨터에서의 활용을 염두에 둔 것이다 (자료제공: Intel) |
 |
| ▲ 폰테 베키오 SoC는 다섯 가지 공정으로 만들어진 47개 타일의 결합으로 만들어진다 (자료제공: Intel) |
슈퍼컴퓨터에서의 활용을 염두에 둔 Xe HPC의 또 다른 특징은 ‘Xe 링크’를 통한 확장성이다. Xe 링크는 개별 Xe HPC GPU 간 메모리 일관성을 갖춘 연결을 통해, 여러 개의 GPU를 하나의 대규모 GPU처럼 활용할 수 있게 한다. Xe 링크는 Xe HPC 스택당 8개가 제공되어, 최대 8개의 GPU간 직접 연결 구성이 된다. 이를 통해 전체 시스템의 연산 성능은 최대 8개까지 높일 수 있다. 이러한 ‘Xe 링크’를 통한 GPU간 연결은 일반적인 호스트의 PCIe 버스를 사용하는 것보다 더 효율적인 대역폭, 더 낮은 지연시간, 메모리 일관성, GPU간 통신과 호스트와의 통신에 대한 트래픽 분리 등을 기대할 수 있다. 물론, Xe HPC와 호스트 시스템간의 연결에는 가장 범용적인 PCIe 버스를 사용하며, 시스템 구조에 따라서는 PCIe 버스를 사용한 확장도 사용할 수 있을 것이다.
한편, 인텔은 이 Xe HPC 기반 제품 ‘폰테 베키오’에서 OAM 폼팩터 기반 단일 GPU 모듈 뿐 아니라, Xe 링크를 통해 4개의 폰테 베키오를 결합한 서브시스템, 그리고 이 서브시스템과 2소켓 사파이어 래피즈 프로세서 기반 시스템을 결합한 솔루션을 레퍼런스로 제시하고 있고, 이 레퍼런스 시스템이 고속 저지연 네트워크에 연결되면서 스케일아웃 확장된 슈퍼컴퓨터급 시스템이 구현된다. 미국 에너지부가 구축하고 있는 슈퍼컴퓨터 ‘오로라(Aurora)’ 또한 이 시스템의 레퍼런스이기도 한데, 이 시스템을 구성하는 개별 노드는 두 개의 제온 ‘사파이어 래피즈(Sapphire Rapids)’ 프로세서와 6개의 Xe HPC GPU의 Xe 링크 연결로 구성되어 있다.
Xe HPC ‘폰테 베키오’ SoC는 제조 측면에서도 아주 도전적인 방식을 사용한다. 지금까지 대부분의 프로세서와 GPU가 단일 공정, 단일 다이를 전제로 설계되어 왔지만, 폰테 베키오는 주요 빌딩 블록들을 서로 다른 제조 공정으로 만들어지는 타일 형태로 만들고, 이를 2D, 3D 패키징 기술을 통해 수평, 수직 결합해 하나의 패키지로 만든다. 폰테 베키오 SoC는 총 5개 제조 공정으로 만들어진 47개의 타일이 하나의 패키징에 집적되는 형태다. 특히, ‘Xe 코어’가 있는 컴퓨트 타일, 캐시와 메모리 패브릭, 인터페이스 등이 있는 베이스 타일까지도 서로 다른 공정 기반의 타일로 분리되어, 포베로스 기술을 통해 결합된다. 또한 Xe 링크 타일 등 패키징 치원의 주요 인프라는 EMIB 패키징을 위한 타일을 기반으로 배치되어 있다.
이러한 도전적인 패키징 형태는 면적 측면의 이점이나, 추후 설계와 제조 단계에서 다양한 변화에 신속하게 대응할 수 있는 큰 유연성을 기대할 수 있지만, 연결되는 타일 간 대역폭이나 결합 피치에 따른 밀도 등, 제조 공정 측면에서의 난이도가 높다는 과제도 존재한다. 하지만 인텔의 경우 2D, 3D 패키징 모두에서 높은 수준의 경쟁력을 확보하고 있는 만큼, 하나의 거대한 다이 구성보다 유리한 선택이 될 수 있다고 판단했을 것이다. 또한 하나의 패키징에서 다양한 공정을 사용하는 형태의 특성상, 인터커넥트 단계에서의 호환성을 활용하면 추후 제조 공정이나 IP 자체의 변화에 대해서도 좀 더 편리한 대응이 가능할 것으로 보인다.
 |
| ▲ 폰테 베키오는 초기 버전 실리콘으로도 이미 충분히 경쟁력을 입증하고 있다 (자료제공: Intel) |
폰테 베키오에서 서로 다른 공정으로 만들어진 실리콘 타일을 하나의 패키지로 구성한다는 패키징 측면에서의 파격적인 구성에 비하면, 각 타일에 사용되는 공정 자체에 대한 부분은 오히려 사소해 보일 정도다. 하지만 Xe 아키텍처 기반 제품들에 사용된 공정 또한 인텔의 변화를 확인할 수 있는, 눈여겨 봐야 할 부분이다. 인텔은 전통적으로 자사의 핵심 제품에는 자사의 제조 공정을 적용해 온 바 있지만, Xe 아키텍처 기반 제품들에서는 이런 결정에 상당한 변화를 찾아볼 수 있기 때문이다. Xe 아키텍처 기반 제품들 중 Xe LP, HP 기반 제품들은 인텔의 공정을 사용하고 있지만, Xe HPG는 TSMC의 N6 공정을, Xe HPC는 컴퓨트 타일에 TSMC N5, 베이스 타일에는 인텔 7, Xe 링크 타일에는 TSMC N7 공정을 적용할 것으로 발표된 바 있다.
인텔의 핵심 경쟁력 중 하나로 꼽히는 것이 제조 공정이고, 인텔의 제품은 인텔의 공정 기반으로 제조될 것이라는 것이 일반적인 인식이지만, 의외로 인텔 또한 TSMC 등 외부 공정을 사용하는 제품들이 제법 있다. 대표적인 사례가 상당수의 네트워크 포트폴리오 관련 제품들이며, 또한 FPGA 등 외부에서 인수를 통해 확보한 포트폴리오의 경우에는 이를 무리해서 변경하지도 않는다. Xe 아키텍처 기반 GPU 포트폴리오의 경우에는 프로젝트의 방향성과 제품의 특성은 물론, 프로젝트 팀 내부에서의 선호도 등에 따라 적합한 제조 공정을 선택한 것으로도 보인다. 그리고 Xe 아키텍처 기반의 다양한 GPU가 다양한 제조 공정으로 만들어질 수 있다는 것은, 아키텍처 자체의 제조 공정에 대한 유연성 측면을 증명하는 것으로도 평가할 수 있을 것이다.
이러한 복잡한 구성으로 만들어지는 Xe HPC ‘폰테 베키오’는 현재 그 유효성이 입증되고, 고객에 일부 샘플링을 시작하는 단계에 들어섰다. 그리고 초기 버전인 A0 실리콘은 일단 이상 없이 동작한다는 것을 넘어, 현재 수준으로도 주요 AI 워크로드 기반 벤치마크에서 추론과 학습 모두에서 업계의 기록을 경신할 수 있을 수준을 갖추었다는 점을 증명했다. 인텔은 A0 실리콘 수준에서 45 TFLOPS 이상의 FP32 성능, 5TBps 이상의 메모리 패브릭 대역폭, 2TBps 이상의 연결 대역폭 성능을 선보였으며, 또한 4만 3천 개 이상의 초당 이미지 레스넷 추론 성능 및 레스넷 학습에서 3천 4백 개 이상의 초당 이미지를 보여주는 데모를 발표하기도 했다. 그리고 추후 실리콘 수준의 최적화가 진행되면 성능은 지금보다 상당히 더 올라갈 수 있을 것으로 보인다.
한편, 인텔에 있어 GPU를 위한 Xe 아키텍처의 등장은 단순한 IP 추가와 포트폴리오 확장이 아닌, 전략이 바뀌는 중요한 기점으로 보아야 할 것이다. 지금까지 인텔의 전략에서 가장 중요한 자산은 ‘x86’이었고, 모든 것을 x86을 중심으로 하려고 했지만, 앞으로는 시장의 요구에 따르는 적절한 아키텍처를 기반으로 하는 ‘XPU’ 전략이 기조가 될 것이 분명하다. 그리고 이런 변화에서, ‘소프트웨어 정의’ 시대에 x86 기반 프로세서의 역량 또한 꾸준히 요구되지만, 특별한 유형의 작업을 위한 전혀 다른 아키텍처 기반의 ‘가속기’를 함께 사용함으로써, 시스템과 솔루션 차원에서의 성능에 대한 수요를 여전히 채워갈 수 있다. 이런 상황에서, 인텔의 Xe 아키텍처 기반 포트폴리오는 데이터 중심 시대 ‘XPU’ 전략으로의 전환에 중요한 전환점이 될 것으로 기대된다.
Copyright ⓒ Acrofan All Right Reserved.


 마이크로소프트, 이그나이트 2023에서 AI 미래 여는 혁신 ..
마이크로소프트, 이그나이트 2023에서 AI 미래 여는 혁신 .. 네이버 두 번째 IDC '각 세종', "초대규모 AI , 클라우드 등..
네이버 두 번째 IDC '각 세종', "초대규모 AI , 클라우드 등..
 오토모빌리 람보르기니 최초의 플러그인 하이..
오토모빌리 람보르기니 최초의 플러그인 하이.. 로터스의 하이퍼 SUV 엘레트라, 국내 판매 가..
로터스의 하이퍼 SUV 엘레트라, 국내 판매 가..